BY
The BY keyword is used to set a minimum level of granularity by which a metric can be broken down. BY effectively sets an aggregation floor, overriding visualization attributes that would serve to break the metric down into smaller units of granularity than is specified in the BY clause.
Syntax
SELECT … BY …
SELECT metric BY attribute
SELECT metric BY attribute1, attribute2
Examples
SELECT {metric/Payment} BY {label/date.year}
SELECT {metric/Payment} / (SELECT {metric/Payment} BY {label/date.year})
SELECT {metric/Payment} BY {label/date.quarter}, {attribute/department}
By Clauses with One Attribute
The example below shows customer support ticket resolution time by month
and quarter. Note how the BY clause is used in the third column to
establish that the metric values should not be broken down by any date
attribute smaller than Quarter. The effect of the BY keyword can be
seen by comparing column 3 and column 2 cell values. Even though the
visualization’s Month/Year attribute breaks visualization data in column 2 down by
month, column 3 data remains at the Quarter level.
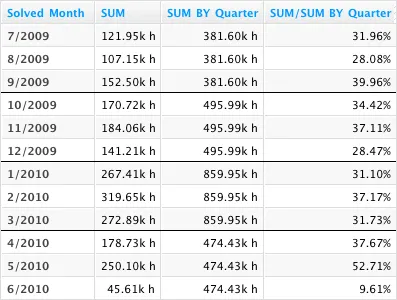
Column 4 provides an interesting use case for the BY keyword: it displays the percent share of the total resolution time in a quarter that can be attributed to each month. This is found by dividing the metric from column 2 by the metric from column 3 using the following syntax:
SELECT(SELECT SUM(metric/resolution_time)) / (SELECT SUM(metric/resolution_time) BY Quarter)
Continuing on with this example, note what happens when we replace the visualization’s Month attribute with a Year attribute (with larger granularity than the metric’s Quarter BY attribute). The chart below shows that the BY keyword no longer affects the data returned by the metric in column 2.
The BY keyword provides a floor - or minimum aggregation level - at the
Quarter level, but does not affect metric data that is aggregated at
the larger Year level of granularity.

By Clauses with Multiple Attributes
The BY clause also supports multiple attributes, including non-date attributes. For example, the syntax below sets an aggregation floor at the Quarter and Department levels.
SELECT SUM({metric/payment}) BY {label/date.quarter}, {attribute/department}
Due to the second attribute in the clause above, sub-attributes of
Department like Product_Team or Employee could be added to a
visualization definition, but values returned by this metric would still be
aggregated at the Department level.
By Clauses with Datasets
You can replace attributes with datasets in BY clauses and represent their granularity.
This provides the same result as using primary key attributes if datasets have the primary keys defined.
SELECT AVG( SELECT ({metric/order_amount}) BY {dataset/order_lines} )
The order_amount metric multiplies price by quantity.
The metric described above calculates the average of order_amount per each record of the order_lines dataset.