COUNT
Use COUNT to return the number of unique values for an attribute or the number of dataset records.
Syntax
COUNT uses the following syntax:
| Form | Syntax | Example |
|---|---|---|
| single parameter | SELECT COUNT(attribute) | SELECT COUNT({attribute/order_id}) |
| two parameters | SELECT COUNT(attribute, primary_key) | SELECT COUNT({attribute/order_id}, {attribute/campaign_id}) |
SELECT COUNT(attribute, dataset) | SELECT COUNT({attribute/order_id}, {SELECT COUNT({attribute/order_id}, {dataset/campaigns}) | |
| with USING | SELECT COUNT(attribute) USING primary_key | SELECT COUNT({attribute/order_id}) USING {attribute/campaign_id} |
SELECT COUNT(attribute) USING dataset | SELECT COUNT({attribute/order_id}) USING {dataset/campaigns} |
Single-Parameter Version
The single-parameter version of COUNT dynamically gets the context of where to count from the visualization it is used in. In cases where the context is ambiguous, the count will be computed on all particular contexts and results from all counts will be joined together.
The following image shows a model with the fact datasets Purchases and Sales and
has both datasets connected to the Store ID and Product ID attributes.
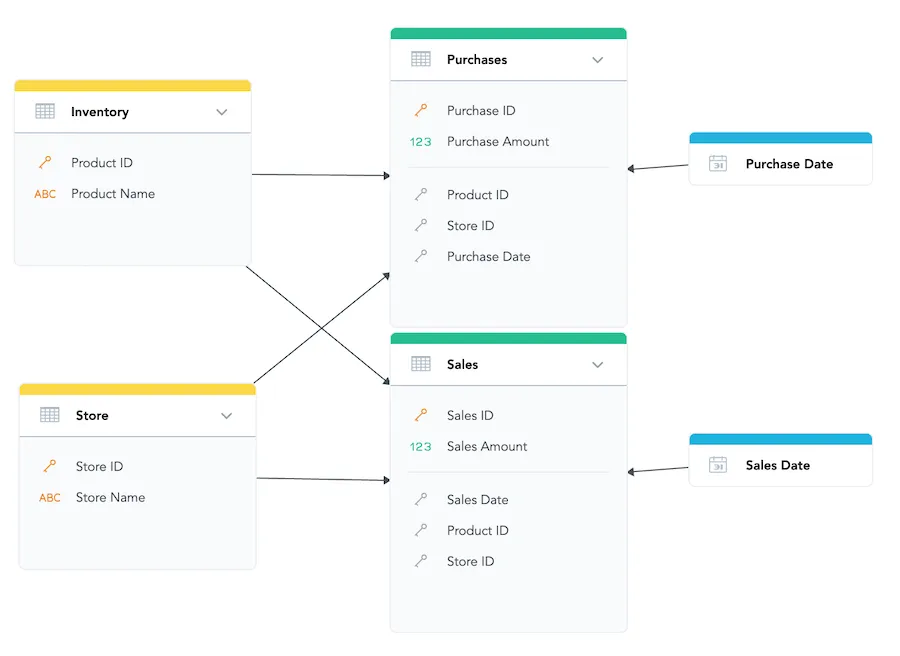
If you build a visualization to display the count of products per store with SELECT COUNT({label/inventory.productid}) and slice it by Store, it is ambiguous whether the visualization should display the number of unique products that have been purchased by store or the number of unique products that have been sold by the store. In such a case, both the number of unique products and the number of unique products that have been sold by the store will be computed and the number of unique products that have been sold or purchased by the store will be displayed.
Notice that in cases where another attribute will be provided, for example by filter on Purchases Amount, the context becomes unambiguous and the count will be computed on the dataset Purchases.
Two-Parameter Version
In the two-parameter version, the context where to count the attribute is determined explicitly by the second parameter - the primary key of the dataset.
The primary key is connection point between datasets. It connects the COUNT function’s first parameter to the dataset in which the count is to take place.
Count of Dataset Records
You can use a dataset identifier as the first argument of COUNT as well. The behavior of COUNT slightly changes depending on whether a primary key is defined in the dataset.
If there is a primary key, the number of unique values of the primary key attribute is returned.
If there is no primary key attribute, the count of all records (including possible duplicates) is returned.
| Form | Syntax | Example |
|---|---|---|
| single parameter | SELECT COUNT(dataset) | SELECT COUNT({dataset/order_lines}) |
Specifying COUNT Context Resolution with USING
In a metric, USING provides a hint for which context should be used. The context for the computation of COUNT may be ambiguous if there are multiple fact datasets in your logical data model that relate to a counted attribute.
Let us use the example model again:
To create a metric that resolves with a specific context, you can specify USING in your metric like in the following
example: SELECT COUNT({label/inventory.productid}) USING {label/purchases.purchaseid}.
With this example, the visualization will show the number of uniquely purchased products per store
because the attribute Purchase ID from the Purchases dataset is in the USING clause.
The attribute in the USING clause can be any attribute which uniquely determines the correct context. For example, you
can also use an attribute from the Purchase Date dataset in the USING clause. This uses the Purchases dataset as
the context because the Sales dataset has no relationships to Purchase Date:
SELECT COUNT({label/inventory.productid}) USING {label/purchasedate.year}