Headless BI x Data Lakehouse


Building analytics has become faster and easier with the latest advances in cloud technologies, but current analytical solutions still have critical drawbacks as we strive to provide consistent, real-time analytics for various use cases. Two such pain points are the physical movement of data between different systems and the tight coupling between analytics and consumption.
The data-movement problem arises at any step in the analytical stack that requires data to be physically moved or copied; with the resulting side effect being that of data latency and duplication. Meanwhile, the second issue is that data tools and applications consuming the data yield inconsistent results; due to them using their own proprietary data models, calculations, and metric definitions.
To solve these shortcomings, we need to replace cumbersome data pipelines and decouple analytics from the presentation layer to provide consistent metrics to our data consumers.
GoodData Meets Dremio
GoodData and Dremio have implemented integration between GoodData.CN, the cloud-native analytics platform, and Dremio’s SQL Lakehouse Platform to better meet the needs of developers looking for real-time, consistent, and open analytics capabilities — without moving any data.
While GoodData’s headless BI engine offers developers the ability to build modular, scalable, and decoupled analytics consumable anywhere, Dremio connects to multiple data lake sources and enables the user to query data directly on the data lake storage without having to move or copy the data. Thus, you can build an analytical stack that reduces the number of steps which have the ability to compromise the quality and credibility of your data and make consistent analytics available on any BI platform, data science tool, ML/AI notebook, and application.
From Multiple Data Sources into Virtual Datasets
Dremio’s SQL Lakehouse Platform allows users to perform interactive BI directly on the data lake without having to move or copy data. Dremio can connect to multiple data lake sources including S3, ADLS, GCS as well as external sources such as Postgres and SQL Server. Dremio’s Apache Arrow-based SQL query engine enables users to perform lightning-fast interactive queries on multiple datasets from multiple sources.
Users can also build out a unified semantic layer in Dremio that enables self-service analytics with the data at its source. Dremio’s semantic layer empowers data analysts and data scientists to discover, curate, analyze, and share datasets in a self-service manner. With Dremio, users can create virtual datasets built on top of the immutable physical datasets found in sources. With the virtual datasets, users now have the ability to join datasets without having to move or copy the data.
Open and Consistent Real-Time Analytics for Every Data Consumer
GoodData.CN is developed based on an API-first approach. The platform’s REST API layer with OpenAPI specification enables you to generate clients in various languages, making them fully compatible with the APIs. GoodData provides Javascript and Python SDKs; both based on the generated clients, which can be extended by any use case. Moreover, with the platform’s containerized microservice architecture, GoodData.CN can be deployed into your stack — in any cloud — as a microservice, making it highly scalable and performant.
GoodData’s headless BI engine utilizes a semantic model that translates the underlying data structures into easy-to-understand, reusable abstractions that define the relationships between datasets. Thanks to this abstraction layer, you don’t have to interact with multiple different physical data models when analyzing the data. Additionally, the layer allows you to change the underlying physical data or the structure of the source data without breaking the downstream analytics.
With the semantic model taking care of joins, sub-joins, and GROUP BYs, you can build your analytics on top of composable and context-aware metrics instead of writing hundreds or thousands of SQL queries. The composable metric design streamlines metric management and, when a metric is modified, the changes are immediately applied wherever that metric is used, eliminating the need to find and update each affected query individually. Furthermore, by abstracting away the complexities of SQL, GoodData enables your common business users to write metrics directly from the GUI without advanced SQL skills, thus freeing up your IT resources.
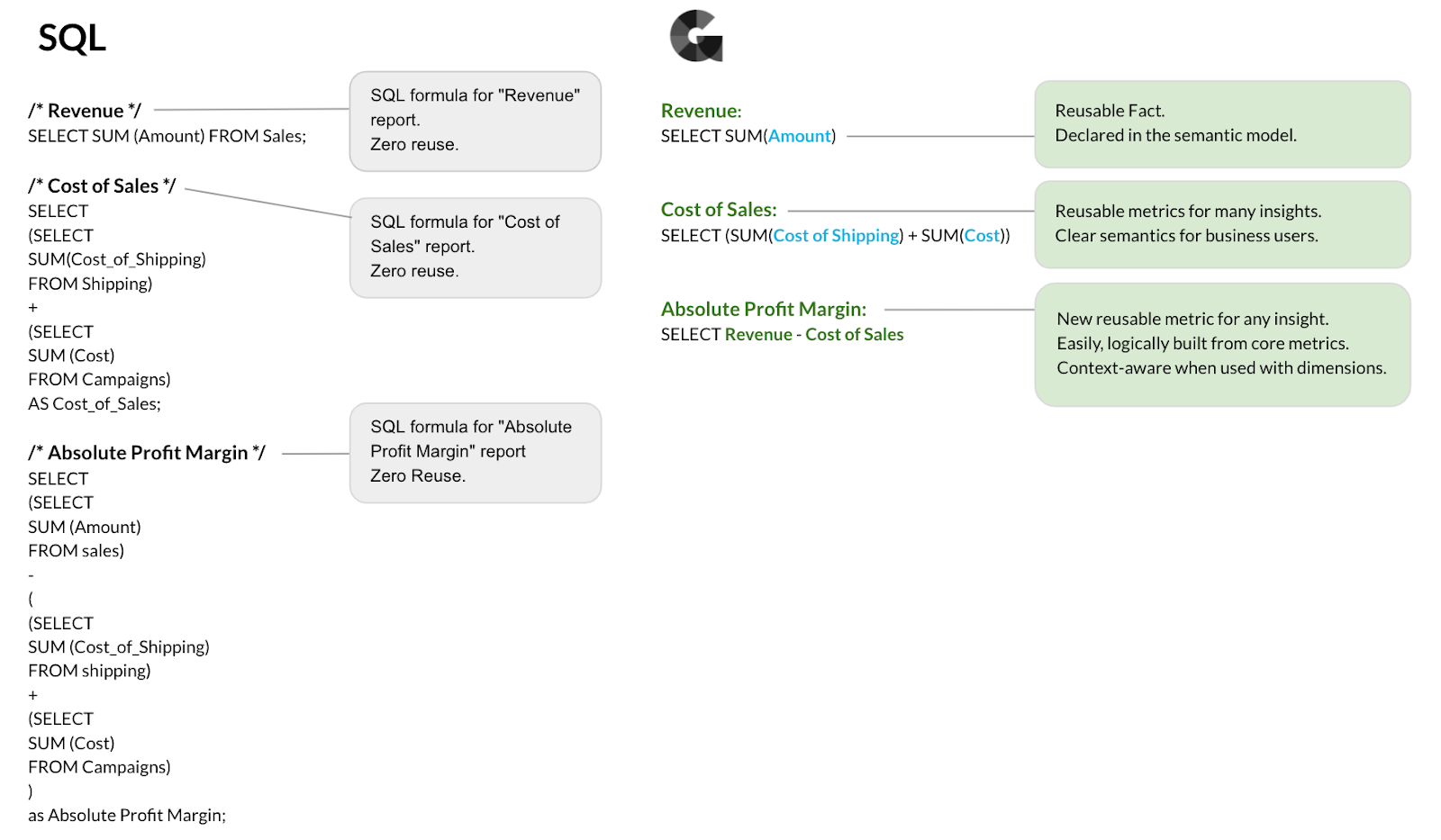
All of the metrics are stored in a single, governed metrics layer, which you can expose as a shared service to your entire toolset, organization-wide. By decoupling analytics from consumption, the headless BI engine allows your applications and BI/ML/AI tools to access the metrics layer — via APIs and standard protocols — and consume the standardized metric definitions in real-time. Due to this centralized metrics consumption, all of your data engineers, analysts, and end-users can work with the same consistent data, with the tools of their choice.
GoodData also offers easy-to-use analytics tools and dashboards — embeddable into your applications — for data exploration. Alternatively, you can use the powerful GoodData.UI SDK to create custom analytical applications that interact directly with GoodData.CN APIs and work with UI frameworks such as React, Angular, and Vue, as well as pure JavaScript. The component library allows you to build custom interfaces for all use cases, tailored to their specific requirements. With GoodData, you can provide real-time analytics to all your data consumers in any way they want to consume it.
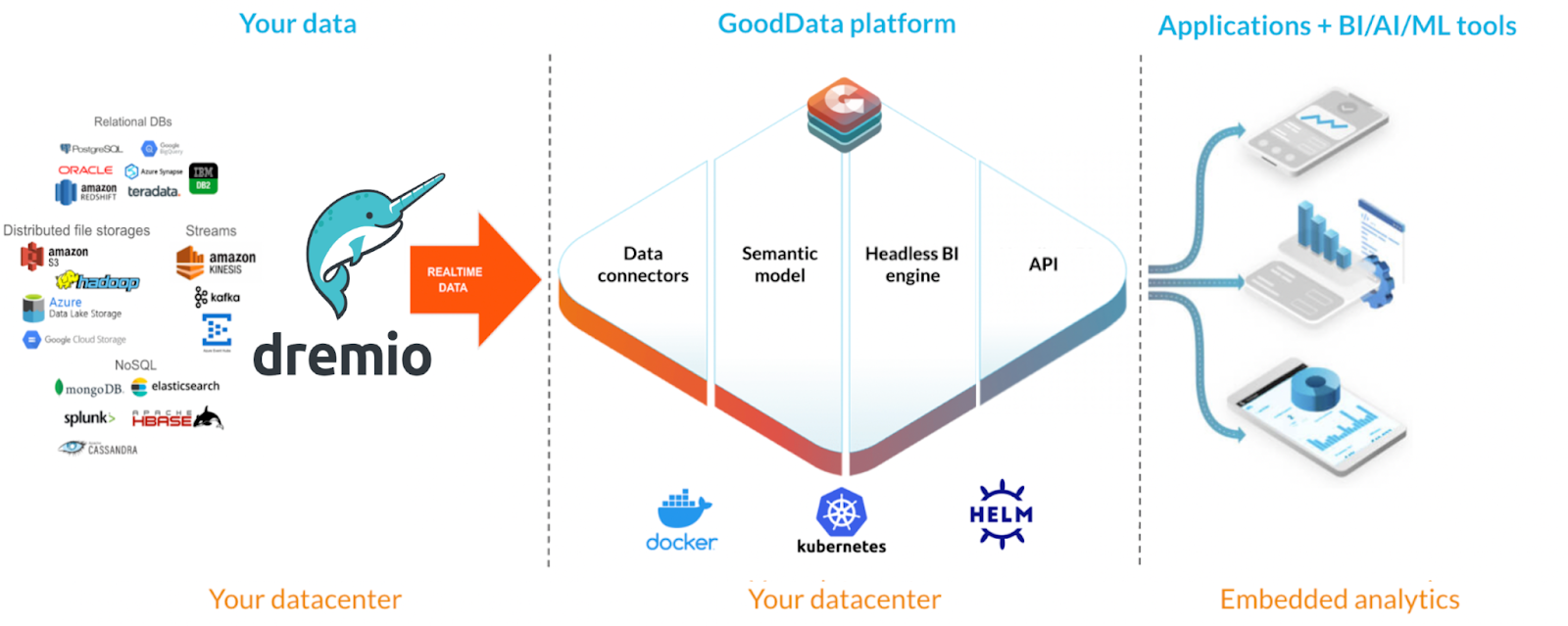
While the data lakehouse replaces your cumbersome data pipelines by combining various heterogeneous data sources — like SQL-based alongside NoSQL — without moving the data, headless BI eliminates the need to rebuild data models and metrics for each data tool. You can create a “single version of truth” once and ensure that everyone working with your data is making decisions based on the same, consistent analytics — in real-time.
Build It Yourself
Do you want to avoid copying your data while providing consistent, real-time analytics to all your data consumers? GoodData and Dremio offer the building blocks required — GoodData.CN Community Edition & Dremio Community Edition — for free. To learn more, visit our website or follow GoodData’s Dremio integration documentation to get started and build a headless BI stack on top of a data lakehouse.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursIf you are interested in GoodData.CN, please contact us. Alternatively, sign up for a trial version of GoodData Cloud: https://www.gooddata.com/trial/

