FlexConnect: Build Your Own Data Source
Written by Lubomir Slivka |

Table of Contents
Over the years, we have heard from customers — particularly those running GoodData in-house on their own premises — that they would like to integrate data from various internal APIs into their reports and dashboards in real time.
These customers often have critical data in legacy and proprietary systems, or systems that don’t easily fit into traditional BI solutions — NoSQL, APIs, Machine Learning models, and more.
The importance of integrating this internal data cannot be overstated. Real-time insights from these data sources are often crucial for making informed decisions, optimizing operations, and maintaining a competitive edge. Whether it's up-to-the-minute sales figures, operational metrics, or customer engagement data, having all the relevant information accessible in one place empowers businesses to react swiftly.
Faced with this challenge, we set out to find a solution that would allow our customers to easily integrate data from any source — regardless of format or protocol — into the GoodData platform. Our goal was to create a flexible, robust system that could handle diverse data inputs without sacrificing performance or requiring extensive re-engineering of the existing infrastructure.
In this article, I will explain why and how we embarked on this journey, and the technological and architectural decisions we made to address the need for custom data source integration. Specifically, we'll look into how we leveraged our existing architecture (based on Apache Arrow and Flight RPC) to build a solution that meets these complex requirements, the challenges we faced, the solutions we came up with, and how we extended our FlexQuery subsystem to accommodate this new functionality.
This article is part of the FlexConnect Launch Series. Don't miss our other articles on topics such as API ingestion, NoSQL integration, Kafka connectivity, Machine Learning, and Unity Catalog!
FlexQuery Architecture Overview
Before I describe how we extended GoodData to accommodate the custom data sources, I will give you a brief overview of our architecture. We have a couple of in-depth posts about this if you are interested, but here I will provide just a quick summary.
GoodData computes analytics using a semantic model. Engineers create semantic models that map between the logical world (datasets, attributes, facts, metrics) and the physical world (data source — typically an RDBMS or data warehouse, with tables and views).
GoodData users create reports that work with the logical entities, and our system then translates these reports into physical plans. So, for example, when the data source used by the logical model is a data warehouse, GoodData will build an SQL query to obtain the data, perform additional transformations (such as reshaping, sorting, and adding totals), and then serve this result via an API so that it can be rendered in a visualization.
We have encapsulated all these concepts of the GoodData platform into a subsystem that we call FlexQuery. This subsystem works closely with the semantic model and:
- Creates a physical plan
- Orchestrates execution of the physical plan
- Connects to data sources to obtain raw data
- Transparently caches results and/or intermediate results for fast and efficient reuse
It also performs different types of post-processing operations; to generalize, there are mainly these two:
- Dataframe operations where the data is wrangled or enriched using Pandas/Polars
- Additional SQL operations where the data is post-processed using SQL in our local, dynamically created DuckDB instances
The following diagram provides a high-level outline of the architecture and its interactions. Note that both the intermediate and final computation results are cached for reuse. If the system already finds the data in caches, it will short-circuit all the complex processing and transparently work with the cached data.
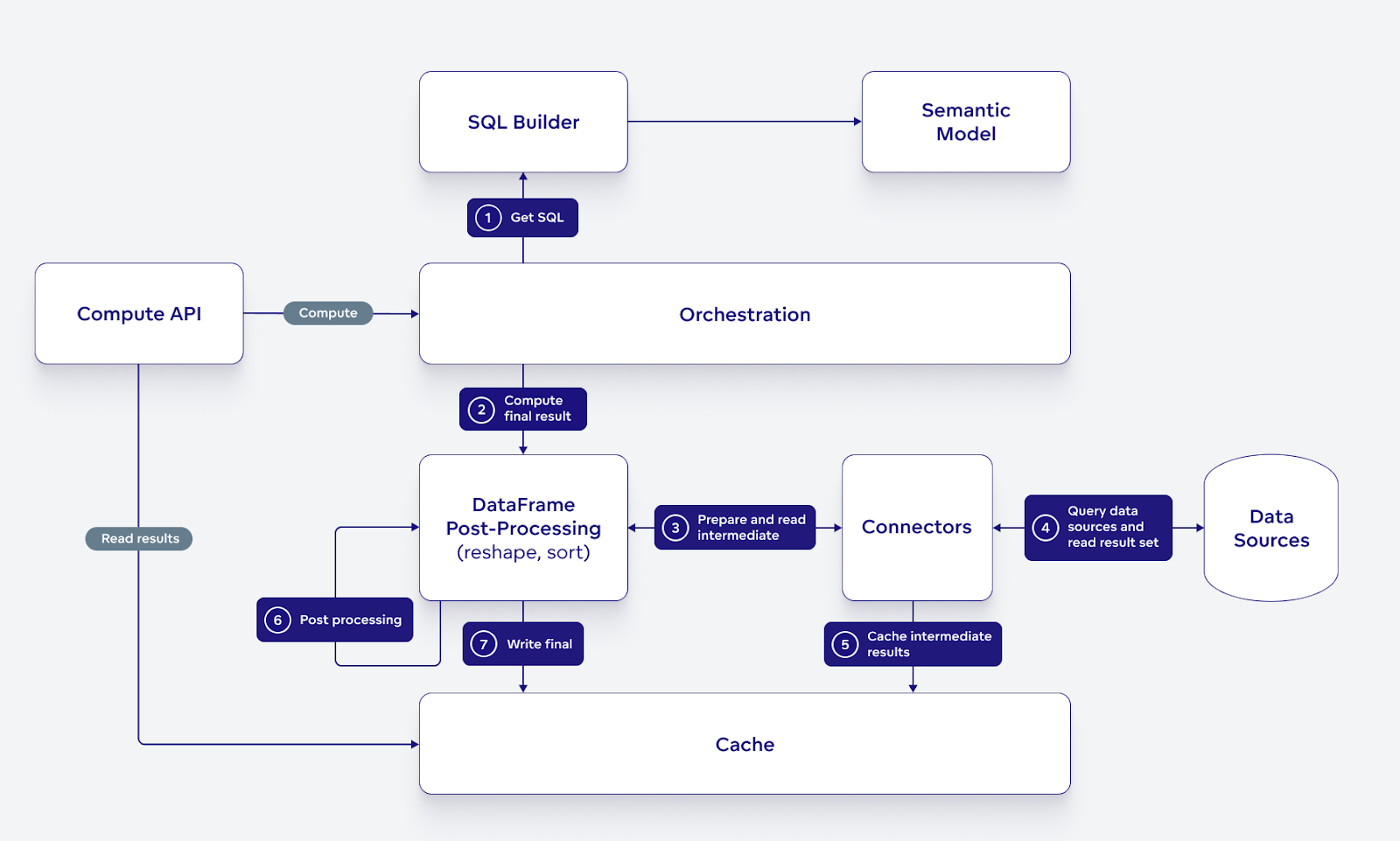
FlexQuery is built fully on top of Apache Arrow. We have adopted both the format and the Arrow Flight RPC as the API for the data services. We took great care to design our use of Flight RPC so that the layer of our data services allows for data processing composability.
In other words, because all the data in FlexQuery is in Arrow and all the data services implement the same API (the Flight RPC), we can easily combine and recombine the existing data services to address new requirements and use cases.
Take, for example, the data service that allows SQL post-processing using DuckDB. This data service is important — it will play a huge role later in the article. The data service is designed to fulfill the following contract: generate a new Flight by running SQL on top of data from one or more other Flights. The service obtains Arrow data for the input Flights (described by their Flight descriptors), loads the data into DuckD, and runs arbitrary SQL. The result is then either streamed out for one-time reading or transparently cached (as a flight path) for repeated reads.
In the end, our service that performs the SQL post-processing does not care where the data comes from—the only thing that matters is that it is in Arrow format. The data may come from caches, an RDBMS, a data warehouse, file-on-object storage, or an arbitrary non-SQL data source — it may even be the case that data for each table comes from a different data source.
With such flexibility available, we can quickly create different types of data processing flows to address different product use cases. In the next section, I will describe how we leveraged this to enable custom data sources.
Custom Data Source With Arrow and Flight RPC
When we started designing the capability to build and integrate custom data sources with GoodData, we worked with several main requirements:
Simple Integration Contract
The integration contract must be simple, and importantly, must not impose complicated implementation requirements on the custom data source.
For example, establishing a contract where the custom data source receives requests as SQL would not be a good idea — purely because it forces the implementation to understand and act on SQL. The custom data sources may encapsulate complex algorithms, bridge to no-SQL database systems, or even to different APIs.
Seamless Data Source Integration
The custom data source must integrate seamlessly with our existing semantic model, the APIs, and the applications we have already built.
For example, we have a visual modeler for the application that allows users to discover datasets available in the data source and then add them to the semantic model.
Ready for Complex Metrics
Users must be able to build complex metrics on top of the data provided by the custom data source; the data source itself must be shielded from this — our system must do the complex computations on top of the data provided by the data source.
We quickly realized that what we ultimately want to achieve is similar to table functions — a feature supported by many database systems. In short, a table function, or a user-defined table function, has these qualities:
- Takes a set of parameters
- Uses code to return (generate) table data
- Can be used like a normal table
The big benefit of table functions is the simplicity of the contract between the rest of the system and the function itself: the function is called with a set of parameters and expected to return table data.
The table function model is an ideal starting point for our ‘build your own data source’ story:
- The contract is simple — but still flexible enough
- The functions return tables with known schema — this can be easily mapped to datasets in our semantic model
- The return value is a table — which lends itself to additional, possibly complex SQL post-processing on our side
The twist in our case is that these table functions are remote. We want to allow developers to build a server with their functions, register this server to GoodData as any other data source, and then integrate the available table functions into the model. That is where Apache Arrow and the Flight RPC come into play again.
Remote Table Function Invocation
It is straightforward to map an invocation of a table function to Flight RPC: it means generating a new Flight described by a command. In this case, the command contains the name of the table function and a set of parameters. The invocation flow is then the standard Flight RPC GetFlightInfo — DoGet medley as described in the Flight RPC specification.
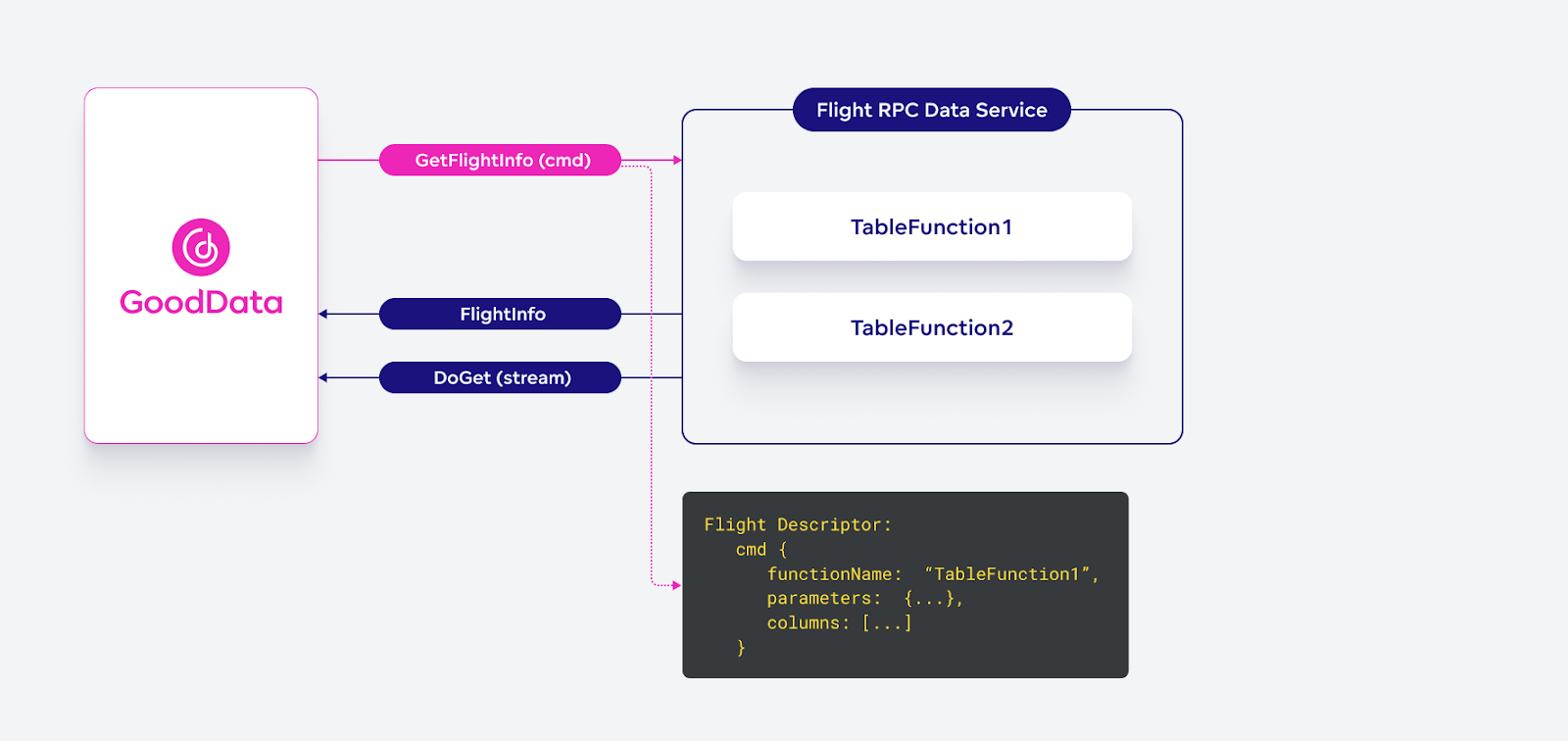
Remote Table Function Discovery
Next, we had to solve how to achieve discoverability of the functions that some Flight RPC data service implements. This is essential in our context because we want to integrate these custom data sources with our existing tooling — which shows all the available datasets in a data source and allows users to drag-and-drop them into the model.
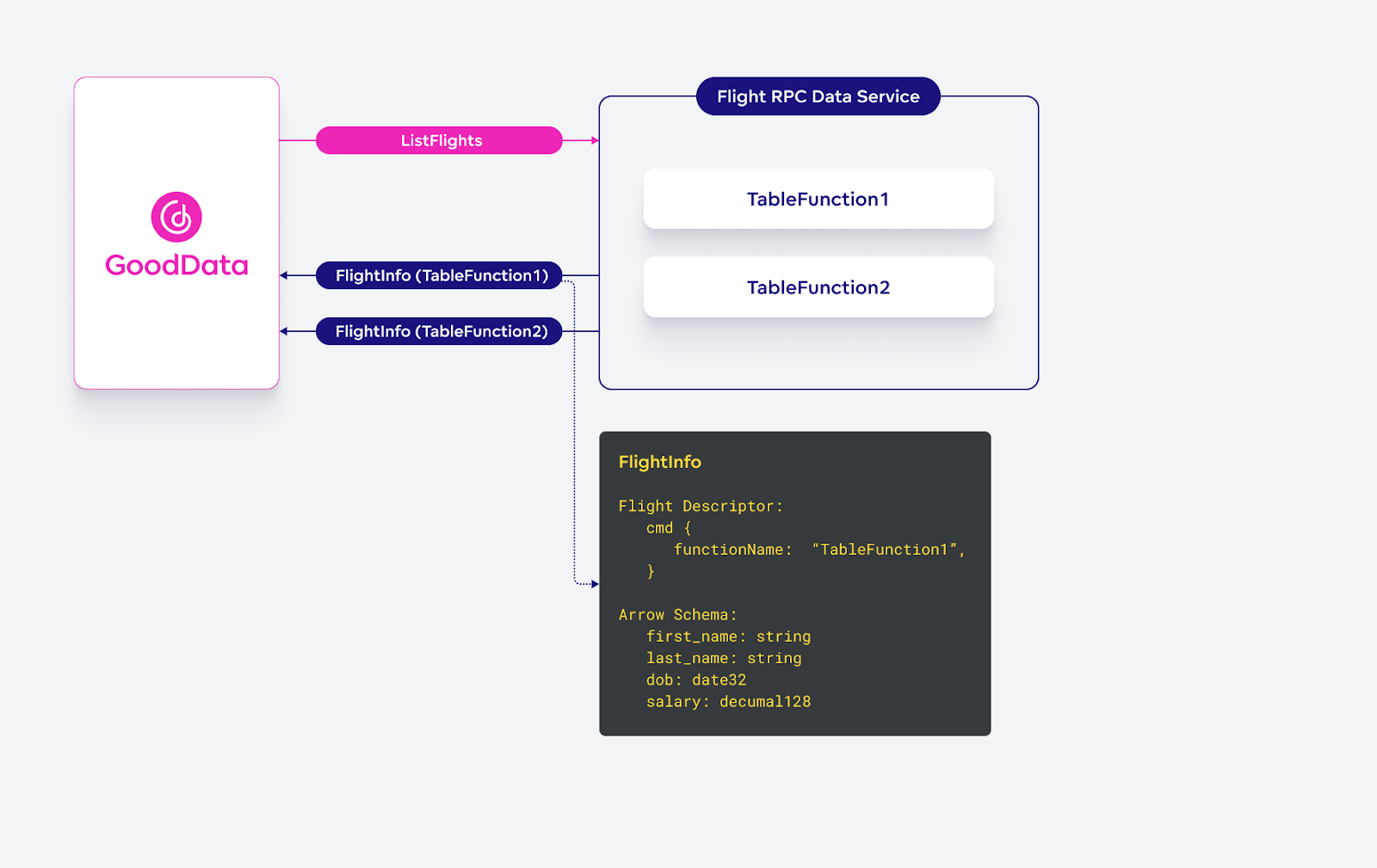
For this, we repurposed the Flight RPC’s existing ListFlights method. Normally, the ListFlights method lists existing Flights that are available on some data service and can be picked up using DoGet.
In our case, we slightly modified the contract so that the ListFlights method returns information about Flights that the server can generate. Each FlightInfo returned in the listing:
- Contains a Flight descriptor that includes a command; the command payload is a template that can be used to build a payload for the actual function invocation
- Contains Arrow Schema that describes the table generated by the function — an essential piece of information needed to create datasets in our semantic model
- Does not contain any locations — simply because the FlightInfo does not describe an existing flight whose data can be immediately consumed
Integration with FlexQuery
At this point, all the pieces of the puzzle are on the table:
- A custom data source exposing table functions
- Discoverability of the functions
- Mapping between semantic model datasets and the functions
- Method for the invocation of the functions
All that remains now is ‘just’ putting the pieces together. This is an ideal place for me to showcase the capabilities and flexibility that FlexQuery provides (we use the ‘Flex’ prefix for a reason).
Data source driver
FlexQuery communicates with data sources using connectors. The connectors use physical connections created by the FlexQuery data source drivers. So, naturally, we had to create a new FlexQuery data source driver.
I don't want to discuss the contract for our FlexQuery connector drivers now. Needless to say, the contract does not require that the data source support SQL — the drivers are free to run queries or list available flights on arbitrary data sources and use completely custom queries or list payloads.
Since the server hosting the table functions is an Arrow Flight RPC server with standard semantics, we created a FlexQuery driver that can connect to any Flight RPC server and then:
- Run queries by making GetFlightInfo->DoGet calls while passing arbitrary Flight descriptor provided by the caller
- Perform ListFlights and pass arbitrary listing criteria provided by the caller
This driver is then loaded into FlexQuery’s connector infrastructure, which addresses the boring concerns such as spinning up actual data source connectors, distributing replicas of data source connectors across the cluster, or managing connection pools.
Once the driver is loaded into the FlexQuery cluster, it is possible to add new data sources whose connections are realized by the driver = FlexQuery can now connect to Flight RPC data sources.
Integrating with the semantic model and compute engine
The system's ability to physically connect and run queries on a Flight RPC data source is not the end of the story. The next step is integrating into the semantic model, running complex computations on top of data obtained from table functions, and post-processing the intermediate results to their final form.
Integration into a semantic model is very straightforward: all we had to do was add an adapter to the FlexQuery component, which is responsible for discovering semantic model datasets inside a data source.
In this case, the adapter calls out to ListFlights of the data source and then performs some straightforward conversions of information from FlightInfo to the semantic model’s data classes. The FlightInfo contains information about the function and an Arrow schema of the result table; these can be mapped to a semantic model dataset in nearly 1-1 fashion: a table function becomes a dataset, and the dataset’s fields are derived from the Arrow schema.
Declare Datasets Queryable
To make the datasets queryable, we had to declare to our SQL query builder (built on top of Apache Calcite) that all datasets from the new data source can be queried using SQL with the DuckDB dialect.
This enabled the following:
- Simplified Query Building: When a user requests a complex report involving this data source, the SQL builder treats all table functions as existing tables within a single DuckDB database.
- Accurate Column and Table Mapping: When our SQL builder creates SQL, it also pinpoints all the tables and columns of those tables that are used in the query.
Add an Adapter to the Execution Orchestration Logic
Since the new data source doesn’t natively support SQL querying, we need to adjust our execution logic:
- Utilizing FlexQuery’s Data Service: FlexQuery already has a data service that allows SQL post-processing using DuckDB. We leveraged this by dispatching the SQL created by our builder to this existing service and correctly specifying how to obtain data for different “tables.”
- Data Retrieval for Each Table: Data for each table is obtained by calling the FlexQuery connector to the newly added data source. The code constructs a Flight Descriptor that contains all essential remote function invocation parameters — in this case, the full context of the report execution.
- Optimizing Data Handling: As both an optimization and convenience, FlexQuery also indicates to the remote table functions which columns are essential in the particular request. This allows the function to (optionally) trim unnecessary columns.
Performing Post-Processing of Intermediate Results
To further process intermediate results, we reused the existing data service that handles reshaping and sorting any Arrow data in our system. This step is achieved simply by piping the result of the SQL query to the post-processing data service and tailoring the Flight descriptors accordingly, providing an efficient and seamless post-processing workflow.
And that’s it! Now our product supports the invocation of remote table functions and can even perform complex computations on the data they provide. This new logic is hooked seamlessly into the rest of FlexQuery, so these results can then be cached for repeated reads and/or passed to further post-processing using Pandas/Polars.
The following diagram outlines the architecture after we added support for remote table functions. We added new plugins and enhanced existing components with a few adapters (depicted in green) — all the other components were already in place. We reused these existing components by crafting the data processing requests differently.
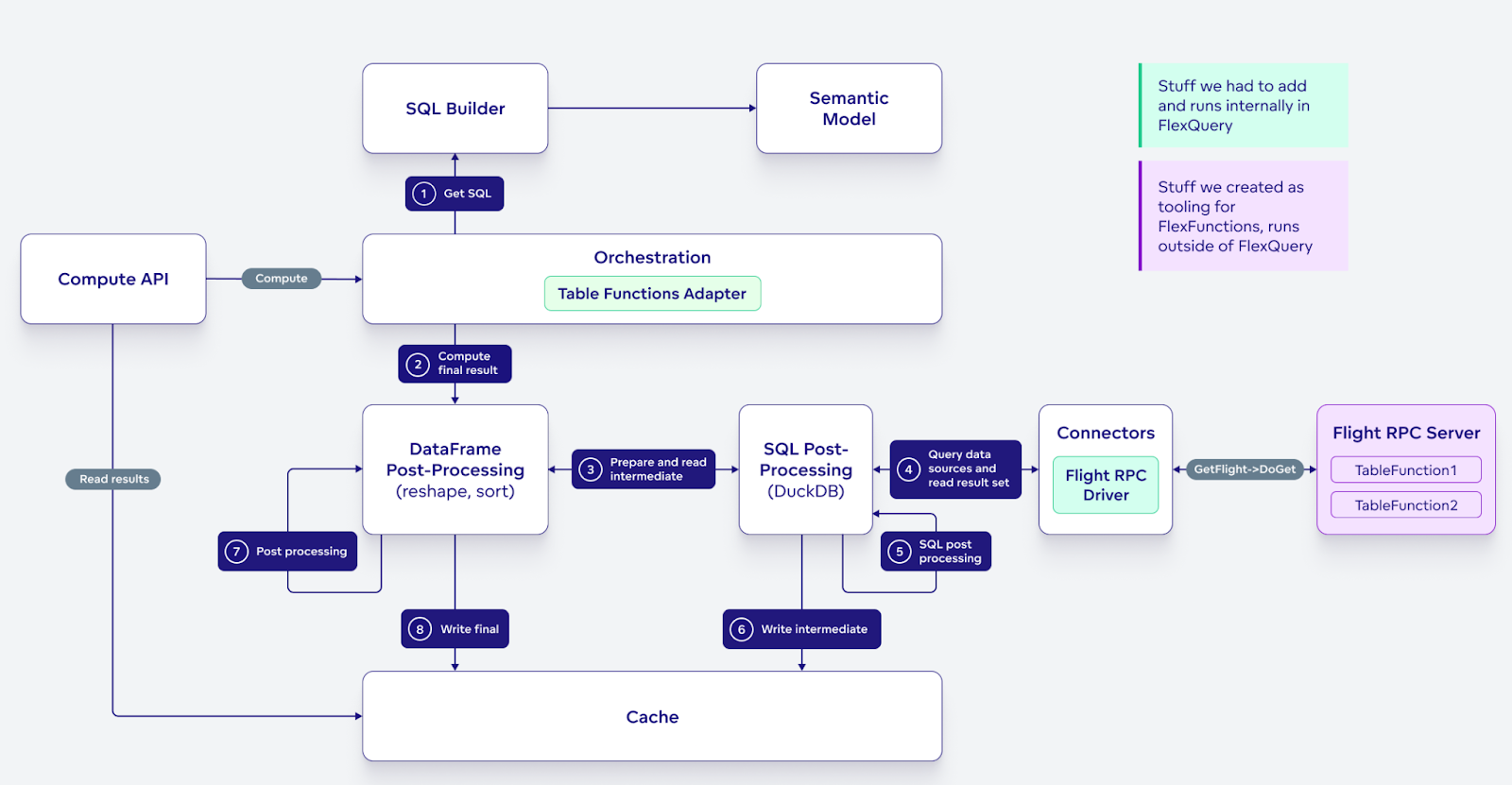
Note that in this picture, every time a component is about to perform a possibly complex computation that results in write of either the intermediate or final result, it will first check for the existence of the data in the cache; requests are short-circuited, and the caller is instead routed to work with the data from the cache. You can find additional details about this and how we implemented transparent caching using Arrow Flight RPC, in the article 'Building Analytics Stack with Apache Arrow'.
The best part was that we already had most of the services and architecture fundamentals ready from our previous effort to enable analytics on top of CSV files.
FlexConnect Introduction
The result of the architecture outlined above is what we call FlexConnect:
- Developers can build custom FlexConnect functions and run them inside a Flight RPC server. The server can then be integrated as a data source with GoodData as regular datasets.
- The data generated by functions can be used in reports by any user.
- Soon™, we will also add the first level of federation capabilities — data blending — which will allow users to mix data from FlexConnect functions with data from other data sources.
A FlexConnect function is a simple contract built on top of Flight RPC that allows the data service to expose custom data generation algorithms. The parts that are specific to GoodData are the commands included in the Flight descriptors.
To help bootstrap the development of the FlexConnect server that hosts custom functions, we have expanded our GoodData Python SDK and included several new packages and a template repository that can be used to build production-ready Flight RPC servers, exposing Flex Functions quickly.
FlexConnect Template Project
A good entry point is the FlexConnect template repository. Its purpose is to quick-start the development of FlexConnect functions; the developers can focus on the code of the function itself and will not need to worry about the Flight RPC server at all. The template is a Python project and uses PyArrow under the covers.
We built this template according to the practices we follow when developing Python libraries and microservices ourselves. It is set up with linter, auto-formatting, and type-checking. It also comes with a sample Dockerfile.
GoodData Flight Server
The Flight RPC server that runs and exposes the developed FlexConnect functions is built using the gooddata-flight-server package. This is our opinionated implementation of a Flight RPC server, influenced heavily by our production use of Arrow Flight RPC.
It is built on top of PyArrow’s Flight RPC infrastructure and solves boring concerns related to running Flight RPC servers in production. It also provides the basic infrastructure to support generating Flights using long-running queries.
This server is otherwise agnostic to GoodData — you can even use it for other Flight RPC data services that do not realize FlexConnect. The server deals with the boilerplate while the developer can plug the actual implementation of the Flight RPC methods.
FlexConnect Contracts
The FlexConnect functions hosting and invocation are implemented as a plugin to the GoodData Flight RPC server (described above). You can find the code for this plugin in our Python SDK.
Within this plugin implementation, there are also schemas that describe payloads used during the function invocation. When GoodData / FlexQuery invokes the function, it gathers all the essential context and sends it as function parameters.
These parameters are included as JSON inside the command sent in the Flight descriptor. We have also published the JSON schema describing the parameters. You can find the schemas here.
This way, if developers prefer to implement the entire Flight RPC server (perhaps in a different language) that exposes remote functions compatible with GoodData, all they have to do is ensure that the implementation understands the incoming payloads as they are described in the schemas.
Conclusion
I hope that this article was helpful for you and provided an example of how Apache Arrow and the Flight RPC can be used in practice, and how we at GoodData use these technologies to fulfill complex analytics use cases.
Speaking as an architect and engineer, I must admit that since we adopted Apache Arrow, we have never looked back. Combined with the sound and open architecture of FlexQuery, we are building our product on a very solid and well-performing foundation.
Learn More
FlexConnect is built for developers and companies looking to streamline the integration of diverse data sources into their BI workflows. It gives you the flexibility and control you need to get the job done with ease.
Explore detailed use cases like connecting APIs, running local machine learning models, handling semi-structured NoSQL data, streaming real-time data from Kafka, or integrating with Unity Catalog — each with its own step-by-step guide.
Want more details about the bigger picture? Connect with us through our Slack community for support and discussion.
Written by Lubomir Slivka |
Related content
Read more

