The Data Value Chain: Redefined


Read this blog on Roman Stanek’s Medium profile.
Last month, Snowflake — a cloud data platform — posted the largest IPO in software industry history. With a valuation of $70 billion, one might think Snowflake had always been a Silicon Valley darling working on a popular data solution.
This could not be further from the truth.
In reality, Silicon Valley was enamored with Hadoop and Snowflake was seen as an outlier. A $70 billion outlier, to be precise.
The demise of the data warehouse
Data used to be managed in expensive, slow, inaccessible SQL data warehouses. SQL systems were notorious for their lack of scalability. And even experts who understood the data domain well were predicting the end of the enterprise data warehouse as we know it. Here is an example: I build data warehouses. I understand why they’re important, I make a living from them. I also see that traditional, relational data warehouses are on the way out. Their demise is coming from a few technological advances. One of these is the ubiquitous, and growing, Hadoop.
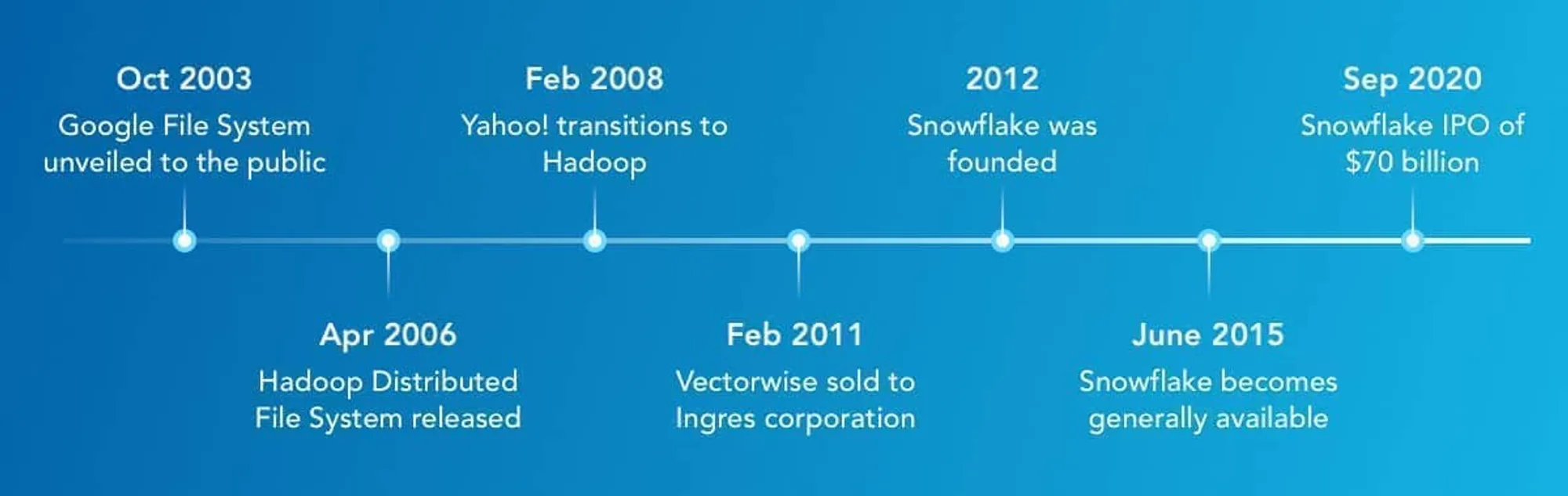
Yes, on April 1, 2006, Apache Hadoop was unleashed upon Silicon Valley. Inspired by Google, Hadoop’s primary purpose was to improve the flexibility and scalability of data processing by splitting the process into smaller functions that run on commodity hardware.
Unfortunately, Hadoop was far too complex, slow, and unwieldy. Meant for unstructured data, the foundations for Hadoop usage were flawed. And so Silicon Valley floundered with Hadoop — for ten years.

Hadoop: a challenging solution
Hadoop’s intent was to replace enterprise data warehouses based on SQL. Unfortunately, a technology used by Google may not be the best solution for everyone else. It’s not that others are incompetent: Google solves problems and serves use cases in a way that few companies can match.
Silicon Valley tried to make Hadoop work. The technology was extremely complicated and nearly impossible to use efficiently. Hadoop’s lack of speed was compounded by its focus on unstructured data — you had to be a “flip-flop wearing” data scientist to truly make use of it.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursOver the years, I’ve discussed Hadoop with industry leaders across Silicon Valley — none of whom were able to explain how mere mortals could use the technology effectively. Unstructured datasets are very difficult to query and analyze without deep knowledge of computer science. At one point, Gartner estimated that 70% of Hadoop deployments would not achieve the goal of cost savings and revenue growth, mainly due to insufficient skills and technical integration difficulties. And seventy percent seems like an understatement.
Eventually, Hadoopers came full circle in their search for an effective end-user tool. They solved this problem by placing a SQL interface on top of Hadoop: the slow data warehouse and inaccessible database became one.
From fluttering flurries to a Snowflake blizzard
Developing in parallel with Hadoop’s journey was that of Marcin Zukowski — co-founder and CEO of Vectorwise. Marcin took the data warehouse in another direction, to the world of advanced vector processing. The GoodData team spent a lot of time evaluating the Vectorwise database but at some point, it became clear to us that the technology was not ready for primetime. Marcin sold the company in 2011 to Ingres Corporation.
In 2012, Marcin and his colleagues Benoit Dageville and Thierry Cruanes started Snowflake, a data warehousing company available exclusively in the public cloud. And Snowflake took a different approach.
Marcin and his teammates rethought the data warehouse by leveraging the elasticity of the public cloud in an unexpected way: separating storage and compute. Their message was this: don’t pay for a data warehouse you don’t need. Only pay for the storage you need, and add capacity as you go.
Naming the company after a discredited database concept was very brave. For those of us not in the details of the Snowflake schema, it is a logical arrangement of tables in a multidimensional database such that the entity-relationship diagram resembles a snowflake shape. … When it is completely normalized along all the dimension tables, the resultant structure resembles a snowflake with the fact table in the middle. Needless to say, the “snowflake” schema is as far from Hadoop’s design philosophy as technically possible.

Snowflake had many nay-sayers: their margins in the public cloud would be terrible, they would compete with Amazon Redshift, and they were steering clear of Hadoop.
None of it mattered. While Silicon Valley was headed toward a dead end, Snowflake captured an entire cloud data market.
The data value chain, redefined
While Snowflake has found success, much of today’s data is still fragmented and disjointed. In the future, I believe this will change.
Snowflake will gain a true set of competitors, which will change the data landscape as we know it. Rather than slow and cumbersome data warehouses, the world’s data will be stored into standardized cloud storage, which will redefine how data is managed in every company.
I call this the “realignment of the data value chain.”
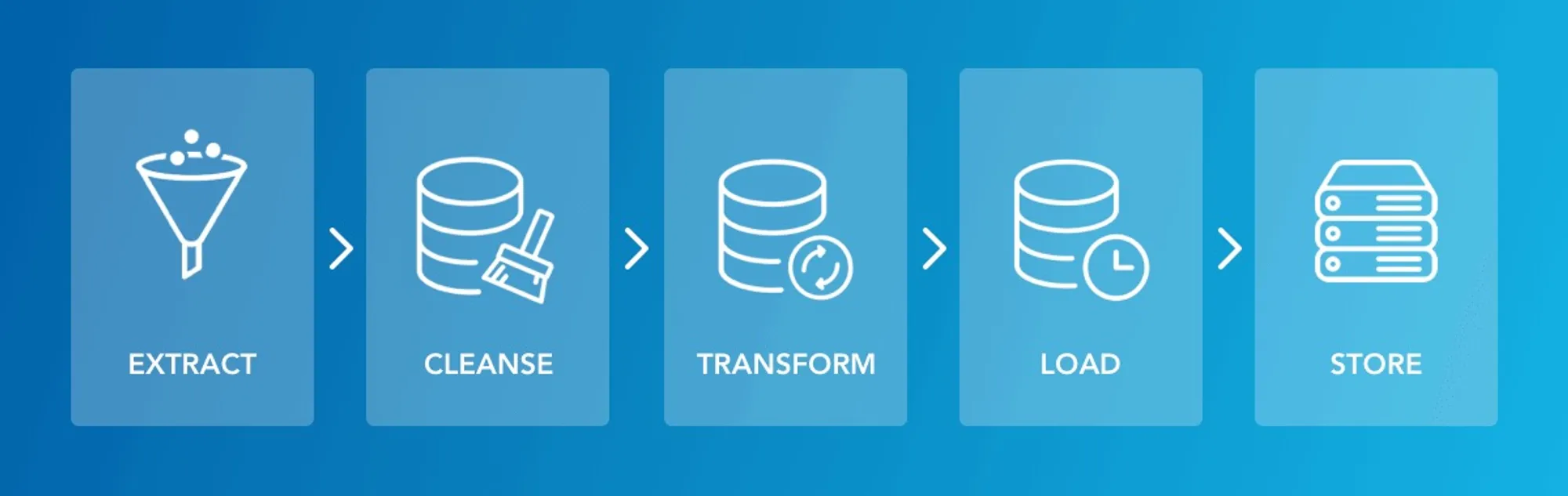
The data value chain is the process by which data is extracted, cleansed, transformed, loaded, and stored. Today’s on-prem data value chain is fragmented. Data constantly moves between various systems and applications, adding friction to gaining insights. In the future, data will be created, managed, accessed, analyzed, and integrated in a well-structured and unified cloud data warehouse.
My prediction
This — Snowflake’s success — is the first of many steps, the first domino if you will. Now that the data is mobilized, the whole ecosystem of the value chain will have to realign.
The companies who fulfill the need for this realignment will outdo their competition. Snowflake will not be the last $70 billion IPO.
Ultimately, this could spawn an even larger success story. I predict that in the future, the new data value chain will result in the software industry’s first $100 billion IPO.
Cover image by Aaron Burden on Unsplash.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product tours
